ポケモンステータスからタイプを識別してみる Keras編
先日までkerasで2値や多値分類を行ってきました。
elsammit-beginnerblg.hatenablog.com
elsammit-beginnerblg.hatenablog.com
今回はkerasでポケモンのステータスからタイプを分類してみたいと思います。
このタイプ分類ですが、すでにロジスティック回帰などで実施していますが、
kerasだとどれだけ性能が上がるのか確認したく実施してみました!!
elsammit-beginnerblg.hatenablog.com
■利用データ
利用したポケモンのデータですが、こちらに格納されたデータを用いております。
https://drive.google.com/file/d/0Bx6uOB0FHuuSMXdOclZXTHhhSUE/view
■分類内容
今回は、
・ノーマルタイプ
・はがねタイプ
のどちらのタイプなのか分類してみたいと思います。
■データ加工
すでに前回のブログでまとめておりましたが、念のためこちらで再度まとめておきたいと思います。
先ほどのデータはこちらのようにステータスと名前が列として用意されておりました。
こちらのリストからノーマルタイプとはがねタイプを抽出。
poketype2 = "ノーマル" poketype3 = "はがね" with codecs.open("/kaggle/input/pokemon-status/pokemon_status.csv", "r", "utf-8", "ignore") as file: df = pd.read_table(file, delimiter=",") nomal1 = df[df['タイプ1'] == poketype2] nomal2 = df[df['タイプ2'] == poketype2] normal = pd.concat([normal1,normal2]) aian1 = df[df['タイプ1'] == poketype3] aian2 = df[df['タイプ2'] == poketype3] aian = pd.concat([aian1,aian2])
次にノーマルタイプかはがねタイプかの判定を行うためのフラグをデータの末尾に追加します。
def type_to_num(p_type,typ):
if p_type == typ:
return 0
else:
return 1
pokemon_m_n = pd.concat([normal, aian], ignore_index=True)
type1 = pokemon_m_n["タイプ1"].apply(type_to_num, typ=poketype3)
type2 = pokemon_m_n["タイプ2"].apply(type_to_num, typ=poketype3)
pokemon_m_n["type_num"] = type1*type2
pokemon_m_n.head()上記コードを組み合わせて実行してみるとこちらのように選択したいタイプが抽出できかつ末尾に判定用のフラグがセットされております。

最後にテストデータとトレーニングデータに分類すればデータ加工・準備は完了です。
全体のコードはこちらになります。
import pandas as pd from pandas import plotting import codecs import numpy as np def type_to_num(p_type,typ): if p_type == typ: return 0 else: return 1 poketype2 = "ノーマル" poketype3 = "はがね" df = pd.read_csv("pokemon_status.csv") nomal1 = df[df['タイプ1'] == poketype2] nomal2 = df[df['タイプ2'] == poketype2] normal = pd.concat([normal1,normal2]) aian1 = df[df['タイプ1'] == poketype3] aian2 = df[df['タイプ2'] == poketype3] aian = pd.concat([aian1,aian2]) pokemon_m_n = pd.concat([normal, aian], ignore_index=True) type1 = pokemon_m_n["タイプ1"].apply(type_to_num, typ=poketype3) type2 = pokemon_m_n["タイプ2"].apply(type_to_num, typ=poketype3) pokemon_m_n["type_num"] = type1*type2 X = pokemon_m_n.iloc[:, 7:13].values y = pokemon_m_n["type_num"].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0) pokemon_m_n.head()
■kerasによるポケモンタイプ分類
ではkerasで分類してみます。
今回はノーマルタイプとはがねタイプを分類してみるため、2値分類になります。
そこで、kerasのモデルをこちらのように作成。
#モデルの定義 model = models.Sequential() model.add(layers.Dense(64, activation="relu", input_shape=(6, ))) model.add(layers.Dropout(0.2)) model.add(layers.Dense(64, activation="relu")) model.add(layers.Dropout(0.2)) model.add(layers.Dense(1, activation="sigmoid")) #モデルの構築 model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
モデルですが、
説明変数は6項目ありますので入力層への入力を6次元に設定。
さらに中間層(隠れ層)を64層用意し、
最後にシグモイド関数により2値分類する
といった構成にしました。
さらにモデルを構築するにあたり、
最適化関数としてrmspropを利用しました。
ではこちらのモデルを用いてポケモンのタイプ分類してみたいと思います。
全体のコードはこちら。
import tensorflow as tf from sklearn import datasets from keras.models import Sequential from keras.layers import Dense, Activation from matplotlib import pyplot #モデルの定義 model = models.Sequential() model.add(layers.Dense(64, activation="relu", input_shape=(6, ))) model.add(layers.Dropout(0.2)) model.add(layers.Dense(64, activation="relu")) model.add(layers.Dropout(0.2)) model.add(layers.Dense(1, activation="sigmoid")) #モデルの構築 model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy']) #学習の実行 history = model.fit(X_train,y_train,epochs=100) #エポック毎のaccuracy結果グラフ化 pyplot.plot(history.history['accuracy']) pyplot.title('model accuracy') pyplot.ylabel('accuracy') pyplot.xlabel('epoch') pyplot.legend(['train', 'test'], loc='upper left') pyplot.show() #評価の実行 score = model.evaluate(X_test,y_test,batch_size=1) print(score[0]) print(score[1])
エポック数ですが100を設定しました。
トレーニングした結果はこちら。
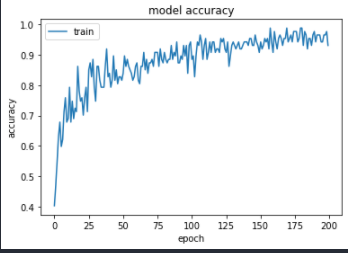
テスト結果ですが、
Loss:0.279 Accuracy:0.908
となりました。
結構高い結果が得られました!!
しかしながら、以前実施したロジスティック回帰の場合には0.943であったので少し悪い結果になってしまいました。。。
■別のタイプで確認してみる
ノーマル、はがねタイプの分類では負けてしまいましたが、、、
ほのお、みずタイプでロジスティック回帰とKerasで比較をおこなってみました。
結果ですが、
【ロジスティック回帰】
testデータに対するscore: 0.738
【Keras】
testデータに対するscore:0.803
といった結果になりタイプによっては性能が高いことが分かりました。
■最後に
タイプによってはKerasの方が性能がよさそうですね。
どんな法則があるのでしょう??
ちょっと後で調べてみたいな!!と思います。