pandasで2次元配列データを加工する
Kaggleを行う上で用意されているデータの加工は重要なファクターになります。
ですが、Kaggleで用意されているデータは穴が抜けていたり、文字列データであったりと扱いにくい場合が多々あります。
今回はこのような扱いにくいデータを加工する手段についてまとめておこうと思います。
■条件
今回はすでに応募が終了している、
bnp-paribas-cardif-claims-management
コンテストで展開されているデータを利用していきます。
■穴抜けデータの存在確認
まず2次元データに対して穴抜けデータが格納されていないか確認していきます。
コードはこちら。
def kesson_table(df): null_val = df.isnull().sum() percent = 100 * df.isnull().sum()/len(df) cnt = [] val = [] pst = [] for count in range(df.shape[1]): if null_val[count] != 0: cnt.append(count) val.append(null_val[count]) pst.append(percent[count]) cnt = pd.DataFrame(cnt) val = pd.DataFrame(val) pst = pd.DataFrame(pst) kesson_table = pd.concat([cnt, val, pst], axis=1) kesson_table_ren_columns = kesson_table.rename( columns = {0 : 'Number', 1 : '欠損数', 2 : '%'}) return kesson_table_ren_columns kesson_table(train)
kesson_tableが穴抜けデータが存在しないか確認する処理になります。
null_val = df.isnull().sum()
にて各行に対して穴抜けのデータ数をカウントしています。
もし1つでも穴抜けのデータが存在する場合、null_val には0以上の値が格納されます。
このため、
for count in range(df.shape[1]): if null_val[count] != 0: cnt.append(count) val.append(null_val[count]) pst.append(percent[count])
にてnull_valが0ではない。すなわち穴あきデータが存在した場合には確認用の配列に格納していきます。
そして最後に2次元配列でデータを格納し、
値を返します。
cnt = pd.DataFrame(cnt)
val = pd.DataFrame(val)
pst = pd.DataFrame(pst)
kesson_table = pd.concat([cnt, val, pst], axis=1)
kesson_table_ren_columns = kesson_table.rename(
columns = {0 : 'Number', 1 : '欠損数', 2 : '%'})
return kesson_table_ren_columns
■穴抜けデータの保管
まずはこちらのように、ある数値で埋められた列に対して一部セルが空欄であった場合です。
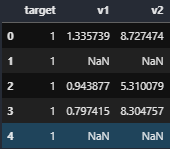
今回はデータの中央値を穴抜けの箇所に代入していきます。
コードはこちら。
train["v1"] = train["v1"].fillna(train["v1"].median()) train["v2"] = train["v2"].fillna(train["v2"].median()) kesson_table(train)
fillna()にて穴抜けになっている箇所に対して括弧内の値で補完します。
補完する値は先ほど記載した通り、
train["v1"].median() train["v2"].median()
により中央値で補完します。
最後に、
kesson_table(train)
にて補完が完了していることを確認します。
次に文字列データについてです。
こちらのように文字列が格納された列に対して穴あきのケースです。

こちらはデータが少なかったり、大多数が同一のデータであれば補完も同じデータにすればよいのですが、
大抵は、
・データ量が多い
・データ種類複数で大多数のデータが見当たらない
ケースがほとんどです。
そこでまずは各要素とその要素ごとをカウントするところから必要になります。
データ種類とカウント数を算出するコードはこちらになります。
import collections c = collections.Counter(train["v56"]) print(c)
v56が列番号にあたります。
今回は2次元配列を用いているため特定の列に対する1次元配列にしてチェックを行っております。
ここで、要素の抽出と要素毎のカウントを行うにあたり、
collections.Counter
を用いています。
collections.Counterですが、例えばこちらのような配列に対して実行をすると、
list = ['a', 'a', 'a', 'b', 'b', 'c'] c = collections.Counter(list) print(c)
こちらのように各要素数に対するカウント数が算出できます。
# Counter({'a': 4, 'c': 2, 'b': 1})
こちらにより再頻出の文字列が抽出できるため、その文字列で穴あきの部分を補完していきます。
例えばv56列で再頻出な文字列が"BW"であった場合、こちらのようなコードで補完が行えます。
train["v56"] = train["v56"].fillna("BW")
こちらは先ほどの数値補完と同じですね。
■文字列の要素を数値に置き換える。
では次に文字列を数値に置き換えてみます。
先ほどのv56列に対して実施してみます。
コードはこちら。
c = collections.Counter(train["v56"]) count = 0 for k in c: train.loc[train["v56"] == k, "v56"] = count count+=1
先ほどのcollections.Counterで各要素をリスト化させることが出来ます。
このリスト化したデータをfor文により一要素毎に数値に置き換えています。
置き換えにあたり、.locを用いています。
.locですが、
DataFrame型変数.loc['行ラベル名', '列ラベル名']
というように指定することで、指定した行、列についての要素が返ってきます。
今回はこの.locにより行列を指定してその要素に対して数値置き換えを行っています。