先日お伝えしました通り、
着席か席を外しているかを判定
を機械学習で行ってみましたのでまとめてみました!!

■判定手段
今回は
①着座中
②席を立っている or 席を外している
のどちらか一方を判定します。
今回も赤外線アレイセンサを用いて着座か否かの状態を取得いたします。
赤外線アレイセンサにより、
着座中の場合、席を立っている場合、席を外している場合、
それぞれの温度マップはこちらの通り。
【着座中】
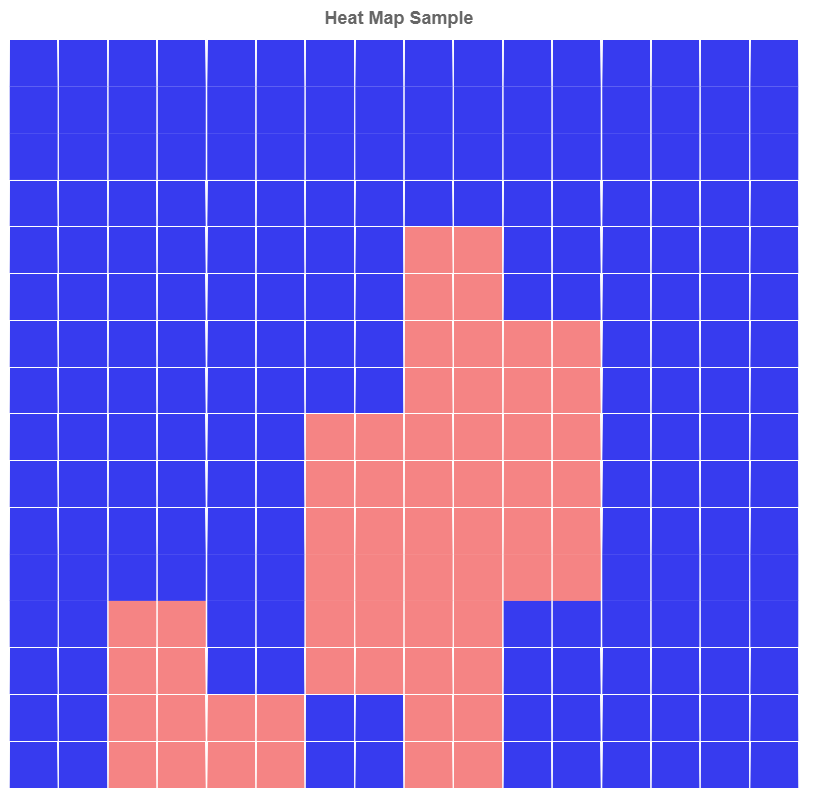
【席を立っている】
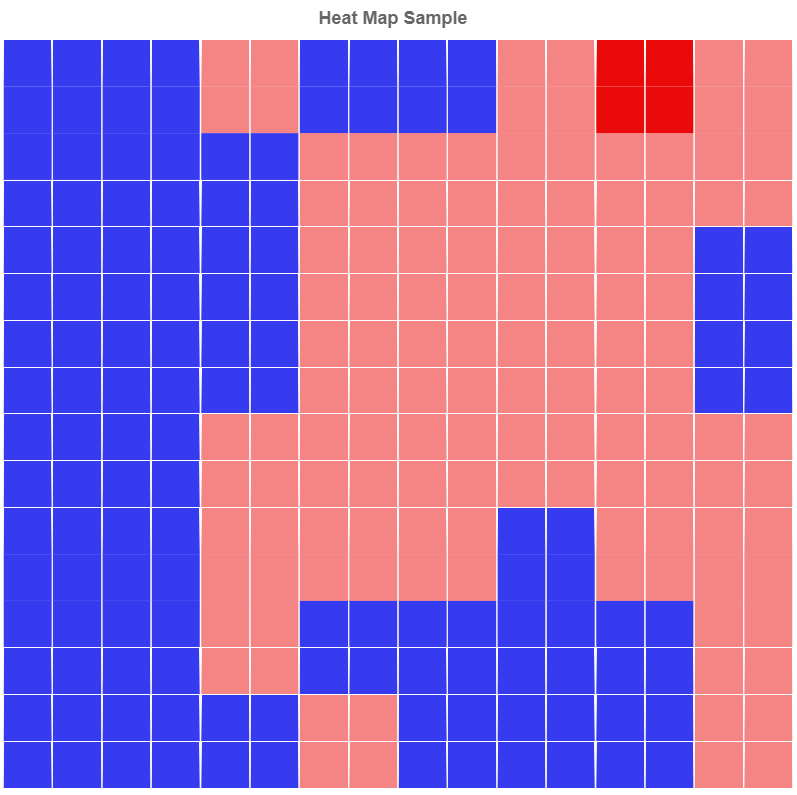
【席を外している】

ここまで温度マップが異なるので、
①、②を自分でアルゴリズム作成して判定してもいいのですが、、、
機械学習でやってみたいと思います!!
■機械学習に向けたデータ収集
まずはデータ収集!!
それぞれのパターン毎に300程度の温度マップを作成していきます。
要するに、、、
・着座中:300データ
・席を立っている:300データ
・席を外している:300データ
の計900データを収集しておきます。
そして、それぞれcsvファイルとして保存。
■機械学習モデル作成
では実際に機械学習用のモデルを作成していきます!!
入力となる温度マップは16x16(256)の1次元データになります。
先ほど収集しておいたデータを用いて機械学習していきます。
コードはこちら。
import csv import codecs import pandas as pd import numpy as np from pandas import plotting import codecs import pickle from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split none = [] standup = [] sitdown = [] status = [] #席を外している場合. csv_file = open('none.csv') f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True) for row in f: row_f = [float(row_s) for row_s in row] row_f.append(0) none.append(row_f) status.append(row_f) #着座中 csv_file = open('sitdown.csv') f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True) for row in f: row_f = [float(row_s) for row_s in row] row_f.append(1) sitdown.append(row_f) status.append(row_f) #席を立つ csv_file = open('standup.csv') f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True) for row in f: row_f = [float(row_s) for row_s in row] row_f.append(0) standup.append(row_f) status.append(row_f) status = np.array(status) X = status[:,0:256] y = np.ravel(status[:,256:257]) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) lr = LogisticRegression(C=1.0,max_iter=300) lr.fit(X_train, y_train) print("-------------------------------------------------") print("train score: %.3f" % lr.score(X_train, y_train)) print("test score: %.3f" % lr.score(X_test, y_test)) print("-------------------------------------------------")
実施していることは各パターン毎にcsvファイルよりデータを収集。
csv_file = open('sitdown.csv') f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
そして、
for row in f:
row_f = [float(row_s) for row_s in row]
row_f.append(1)
sitdown.append(row_f)
status.append(row_f)にて各データ群(16x16の温度マップデータ)に対して、csvファイルで取得したデータをfloat型に変換し、
257個目のデータとして、
①着座中:1
②席を立っている or 席を外している:0
を追加します。
これらの動作を3パターン全て実施した上で、
機械学習実行!!
使用した機械学習モデルはロジスティック回帰です。
X = status[:,0:256] y = np.ravel(status[:,256:257]) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) lr = LogisticRegression(C=1.0,max_iter=300) lr.fit(X_train, y_train)
■学習結果確認
こちらの学習結果をtestデータを用いてtestを実施しました。
結果はこちらの通り!!
------------------------------------------------- train score: 1.000 test score: 0.992 -------------------------------------------------
かなり高い!!
これなら問題なく判定に用いることが出来そうです!!
■学習結果を保存
こちらの学習結果を保存してみます。
保存にはpickleをもちいました。
pickleは下記でインストールできます。
pip install pickle-mixin
学習結果を保存するためにこちらのコードを
lr.fit(X_train, y_train)
以降に追加します。
with open('model.pickle', mode='wb') as f: pickle.dump(lr,f,protocol=2)
実行すると、
model.pickle
というファイルが生成されます。
■最後に
ちょっと長くなってしまったので今回はここまで!!
明日には今回学習・保存した学習結果を用いて着座判定結果をWeb上に表示するサービスを表示させた結果をまとめたいと思います!!