FFMPEGでmp4動画から音声抽出
最近またOpenCVを触って楽しんでおりますw。
OpenCVは色々出来て面白いですね!!
ですが、動画で遊んでいるとどうしても音声も触りたい欲が強くなってしまうのですよね。。。
ということで今回は音声関係について少し触れていきたいと思います。
内容は、mp4動画から音声抽出の方法です。
■事前準備
題名にも記載しました通り、今回はFFMPEGを用いてmp4動画から音声を抽出します。

FFMPEGとは、、、
公式には下記文言がトップに記載されておりました。
A complete, cross-platform solution to record, convert and stream audio and video.
要するにクロスプラットフォームで録画・録音・変換・ストリーミングが行えますよ。
というライブラリになります。
FFMPEGがインスト^ールされていない場合には下記を実行してインストールしておいてください。
【WIndows】
下記が細かくまとめられているため参考にしてください。
fukatsu.tech
【Linux】
下記コマンドを実行ください。
sudo apt install ffmpeg
以降の実行ですが、
・OS:Ubuntu 16.04
で実行した内容をご紹介します。
※おそらくWIndowsでも同様の手順で音声の抽出が可能かと思いますが。
■mp4動画から音声を抽出
では実際にffmpegを用いて音声を抽出してみます。
方法はこちら。
ffmpeg -y -i 動画名.mp4 出力音声名.mp3
たった1行です!!
ついでですが、こちらのように-abオプションを付けるとビットレートの指定も行えるようです。
ffmpeg -y -i -ab 127 動画名.mp4 出力音声名.mp3
■動画の情報を調べてみる
ffmpegを用いると動画の情報を一覧表示で確認することが出来ます。
コマンドはこちら。
ffmpeg -i 動画名.mp4
こちらのコマンドを実行すると下記のように動画のコーデックや音声情報、作成日時などが表示されます。
ffmpeg version 2.8.17-0ubuntu0.1 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 5.4.0 (Ubuntu 5.4.0-6ubuntu1~16.04.12) 20160609
~~~
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from '動画名.mp4':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: mp42mp41isomavc1
creation_time : 2020-09-20 02:22:36
Duration: 00:00:41.22, start: 0.000000, bitrate: 1598 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p(tv, smpte170m), 960x540, 1340 kb/s, 29.97 fps, 29.97 tbr, 30k tbn, 60k tbc (default)
Metadata:
creation_time : 2020-09-20 02:22:36
handler_name : L-SMASH Video Handler
encoder : AVC Coding
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 253 kb/s (default)
Metadata:
creation_time : 2020-09-20 02:22:36
handler_name : L-SMASH Audio Handlerですが、
ffmpeg -i 動画名.mp4
ですと、
At least one output file must be specified
といったエラー??が出力されるようです。
あまりよろしくない場合には、
ffprobe -i 動画名.mp4
を実行すれば上記メッセージが表示されずに情報の表示が行えます。
■(おまけ)動画から音声のみ削除
ffmpegは動画の変換も行うことが出来ます。
例えば、mp4からgifに変換する場合には、
ffmpeg -i 動画名.mp4 出力動画名.avi
を実行すればgif形式の動画が生成できます。
動画から音声のみ削除する場合にはこちらのコマンドを実行すればOKのようです。
ffmpeg -i 動画名.mp4 -an 出力動画名.mp4
オプションとして-anを付与するのみですね。
OpenCVで特定時間から動画再生や早送り・巻き戻し
OpenCVで動画再生方法の記事はいくつか投稿していたのですが、
そういえば、初めから再生させる方法しか知らなかったな!!と思い調べてみました!!
今回は忘れないように備忘録として残しておこうと思います。
■環境
・使用言語:Python3
・OS:WIndows(anaconda)
■動画の途中から再生する方法
OpenCVで動画の途中から再生する方法ですが、
再生したいフレーム番号(数)をセットしてからフレームを読み出していけばOKです!!
全体のコードはこちら。
if __name__ == '__main__': cap = cv2.VideoCapture('ファイルパス') if (cap.isOpened()== False): print("File Open Error") fps = int(cap.get(cv2.CAP_PROP_FPS)) FPS = 1/(fps*1) cap.set(cv2.CAP_PROP_POS_FRAMES, 読み出したいフレーム番号(数)) while(cap.isOpened()): ret, frame2 = cap.read() if ret == True: frame = cv2.resize(frame2 , (int(960/2), int(540/2))) cv2.imshow("Video", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break time.sleep(FPS) else: print("Cap Read Error") cap.release() cv2.destroyAllWindows()
重要なのは、
cap.set(cv2.CAP_PROP_POS_FRAMES, 読み出したいフレーム番号(数))
で、VideoCaptureで読み出した動画データのフレームプロパティ(CAP_PROP_POS_FRAMES)にset関数でフレーム数をセットする。
です。
逆に言えばこれだけです。
フレーム数のセットですので時間換算で考える場合にはFPSから計算してください。
動画データのFPSを取得する場合には、
cap.get(cv2.CAP_PROP_FPS)
を用いればOKです。
今回、FPSをint型で取得したいので
fps = int(cap.get(cv2.CAP_PROP_FPS))
といたしました。
■動画早送り
この、
cap.set(cv2.CAP_PROP_POS_FRAMES, 読み出したいフレーム番号(数))
を用いると早送り・巻き戻しが出来ます。
まずは動画早送り方法です。
コードはこちら。
if __name__ == '__main__': cap = cv2.VideoCapture('Forest - 49981.mp4') if (cap.isOpened()== False): print("File Open Error") fps = int(cap.get(cv2.CAP_PROP_FPS)) counter = 0 speed = 10 FPS = 1/(fps*1) cap.set(cv2.CAP_PROP_POS_FRAMES, 1000) while(cap.isOpened()): cap.set(cv2.CAP_PROP_POS_FRAMES, counter) ret, frame2 = cap.read() counter+=speed if ret == True: frame = cv2.resize(frame2 , (int(960/2), int(540/2))) cv2.imshow("Video", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break time.sleep(FPS) else: print("Cap Read Error") cap.release() cv2.destroyAllWindows()
実施していることは、
while(cap.isOpened()):
cap.set(cv2.CAP_PROP_POS_FRAMES, counter)
ret, frame2 = cap.read()
counter+=speed
で、counter変数にセットされたフレーム数をset関数で動画データのプロパティにセットし、そこのフレームを読み込むことを繰り返しております。
ここでcounter変数にはspeedにセットされた値分だけ増加するコードになっているため、次に読み出すフレームはspeed分だけ加算された数になります。
要するにspeedが10であった場合には、
1⇒11⇒21⇒・・・
といった形で飛び飛びのフレームが読み込まれるようになっている、ということです。
このため、speed分だけ倍速で動画が再生されることになるので早送りのような動画再生が可能になる、というわけです。
一応、
time.sleep(FPS)
の値を短くしても早送りは出来るのですが、、、
読み出し速度や処理速度がネックになり早送りに限界があります。
一方こちらの方法ですと読み込むフレーム数を飛ばしただけ高速で再生できるため何倍にも早送りが出来ます。
■動画巻き戻し
次に動画の巻き戻しです。
と言っても察しの良い方はすぐに分かるかと思います。
そう!!
やることはセットするフレーム数を引き算していけばよいだけです!!
コードはこちら。
if __name__ == '__main__': cap = cv2.VideoCapture('Forest - 49981.mp4') if (cap.isOpened()== False): print("File Open Error") frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) fps = int(cap.get(cv2.CAP_PROP_FPS)) counter = frame_count speed = 10 FPS = 1/(fps*1) cap.set(cv2.CAP_PROP_POS_FRAMES, 1000) while(cap.isOpened()): cap.set(cv2.CAP_PROP_POS_FRAMES, counter) ret, frame2 = cap.read() counter-=speed if ret == True: frame = cv2.resize(frame2 , (int(960/2), int(540/2))) cv2.imshow("Video", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break time.sleep(FPS) else: print("Cap Read Error") cap.release() cv2.destroyAllWindows()
counter変数に全フレーム数であるframe_countを格納し
while(cap.isOpened()):
cap.set(cv2.CAP_PROP_POS_FRAMES, counter)
ret, frame2 = cap.read()
counter-=speed
といった形でspeed分だけフレーム数を差し引いています。
この方法により、
100⇒90⇒80⇒・・・
といった形でフレーム数が差し引かれて読み出されるため巻き戻し再生が行える、というわけです。
■実際に動かしてみる
では実際に比較させてみたいと思います。
結果はこちら。
【通常】

【早送り(10倍速)】
【巻き戻し(2倍速)】
■最後に
今回はフレーム数を指定した特定時間からの動画再生や早送り・巻き戻しについてまとめてみました。
OpenCVを用いると動画早送りや巻き戻しが簡単に行えるのでとても便利だな!!と思いました。
簡単なビデオプレーヤーぐらいなら作れそうなので今度作ってみようかな??
Gtk# + OpenCVSharpでGUIアプリにて動画再生
前回、GtkSharp + OpenCVSharpを用いてGUIアプリに画像を表示してみました。
elsammit-beginnerblg.hatenablog.com
今回はGtkSharp + OpenCVSharpで動画再生させてみたいと思います。
■条件
今回の条件ですが下記になります。
・OS:Ubuntu20.04
・dotnet:.NET 5.0
今回は、
・dotnetでGtkSharpが生成されていること
・OpenCVSharpがインストールされていること
を前提とします。
もし生成出来ていない場合にはこちらをご参考ください。
elsammit-beginnerblg.hatenablog.com
■GtkSharp + OpenCVSharpで動画再生してみる
では動画再生用GUIアプリを実装してみたいと思います。
今回はボタン押下すると動画が再生するようにしてみます。
全体のコードはこちら。
using System;
using Gtk;
using OpenCvSharp;
using OpenCvSharp.Extensions;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
using System.Threading;
using System.Runtime.InteropServices;
using UI = Gtk.Builder.ObjectAttribute;
namespace test2
{
class MainWindow : Gtk.Window
{
[UI] private Label _label1 = null;
[UI] private Button _button1 = null;
[UI] private Gtk.Image testImg = null;
private int _counter;
public MainWindow() : this(new Builder("MainWindow.glade")) { }
private MainWindow(Builder builder) : base(builder.GetRawOwnedObject("MainWindow"))
{
builder.Autoconnect(this);
Thread thread = new Thread(new ThreadStart(()=>{
Application.Invoke(delegate {
ShowMovie();
});
}));
thread.Start();
DeleteEvent += Window_DeleteEvent;
_button1.Clicked += Button1_Clicked;
}
private void Window_DeleteEvent(object sender, DeleteEventArgs a)
{
Application.Quit();
}
private void ShowMovie(){
VideoCapture vcap = new VideoCapture("/home/hiro/dotnet/test2/img/Forest.mp4");
while (vcap.IsOpened())
{
Mat mat = new Mat();
Mat dist = new Mat();
if (vcap.Read(mat)){
if (mat.IsContinuous()){
Cv2.Resize(mat,dist, new OpenCvSharp.Size(240,160),0,0, InterpolationFlags.Cubic);
MemoryStream ms = new MemoryStream ();
var bmp = BitmapConverter.ToBitmap(dist);
bmp.Save(ms, ImageFormat.Png);
ms.Position = 0;
testImg.Pixbuf = new Gdk.Pixbuf(ms);
}else{
break;
}
while (GLib.MainContext.Iteration ()){}
}else{
break;
}
Thread.Sleep((int)(1000 / vcap.Fps));
mat.Dispose();
}
vcap.Dispose();
}
}
}動画を読み出してImage Widgetにフレーム画像を書き込む制御は、
private void ShowMovie(){
VideoCapture vcap = new VideoCapture("/home/hiro/dotnet/test2/img/Forest.mp4");
while (vcap.IsOpened())
{
Mat mat = new Mat();
Mat dist = new Mat();
if (vcap.Read(mat)){
if (mat.IsContinuous()){
Cv2.Resize(mat,dist, new OpenCvSharp.Size(240,160),0,0, InterpolationFlags.Cubic);
MemoryStream ms = new MemoryStream ();
var bmp = BitmapConverter.ToBitmap(dist);
bmp.Save(ms, ImageFormat.Png);
ms.Position = 0;
testImg.Pixbuf = new Gdk.Pixbuf(ms);
}else{
break;
}
while (GLib.MainContext.Iteration ()){}
}else{
break;
}
Thread.Sleep((int)(1000 / vcap.Fps));
mat.Dispose();
}
vcap.Dispose();
}となります。
実施していることは、
・OpenCVSharpで動画からフレーム画像を読み出し。
・読み出したフレーム画像をビットマップデータとしてメモリに書き込み
・メモリに書き込んだビットマップデータをGtkのImage Widgetに書き込み
です。
この、
・読み出したフレーム画像をビットマップデータとしてメモリに書き込み
・メモリに書き込んだビットマップデータをGtkのImage Widgetに書き込み
GtkSharp + OpenCVSharpで実装した時と同じコードになります。
ここで、各フレーム毎にビットマップデータを書き込んだ後に、
while (GLib.MainContext.Iteration ()){}を実行する必要があります。
このglib.MainContext.iteration()がないと、応答なしの状態で画面がフリーズしてしまいます。
glib.MainContext.iteration()について詳細はこちらをご参照ください。
https://developer.gnome.org/pygobject/stable/class-glibmaincontext.html
どうやら、重い処理を実行している場合定期的にキューにたまったデータを吐き出すようにしないと、
画面の更新・描画が発生しないためフリーズしてしまうようです。
■ボタン押下による動画再生
次にボタン押下時に動画再生させる方法ですが、
_button1.Clicked += Button1_Clicked;
といった形でボタン押下時に実行するイベントに対して、
private void Button1_Clicked(object sender, EventArgs a)
{
Thread thread = new Thread(new ThreadStart(()=>{
Application.Invoke(delegate {
ShowMovie();
});
}));
thread.Start();
_counter++;
_label1.Text = "Hello World! This button has been clicked " + _counter + " time(s).";
}といったように、ShowMovie()を別スレッドとして実行すればOKです。
■ボタン押下で動画再生させてみる
では実際に動かしてみます。
結果はこちら!!
ボタン押下したら動画が再生されることが確認できるかと思います。
※動画少し小さすぎました。。。
■注意
一旦ビットマップデータに変換させていることが要因なのか、
動画サイズが大きくなると動画再生が遅くなってしまう現象が発生していました。。。
こちらの方法で動画再生させる場合、あまり動画サイズは大きくしない方がいいかもです。。
■最後に
以前できなかった動画再生を実現させることが出来ました!!
結構自分的には満足!!
もう少しGtkSharpで遊んでみたいと思います。
もし新しく分かったことがあったら備忘録も兼ねてブログに載せていきたいと思います。
Gtk# + OpenCVSharpでGUIアプリに画像を表示
前回OpenCVSharpをdotnetに導入するまでの手順をまとめました。
今回はdotnetで生成したGtkSharp + OpenCVSharpでWindowアプリケーション上に画像を表示させてみたいと思います!!
分かると簡単なのですが、結構ハマったところなので忘れないように備忘録残しておこうと思います。
■条件
今回の条件ですが下記になります。
・OS:Ubuntu20.04
・dotnet:.NET 5.0
今回は、
・dotnetでGtkSharpが生成されていること
・OpenCVSharpがインストールされていること
を前提とします。
もし生成出来ていない場合にはこちらをご参考ください。
elsammit-beginnerblg.hatenablog.com
■GtkSharp + OpenCVSharpで画像を表示
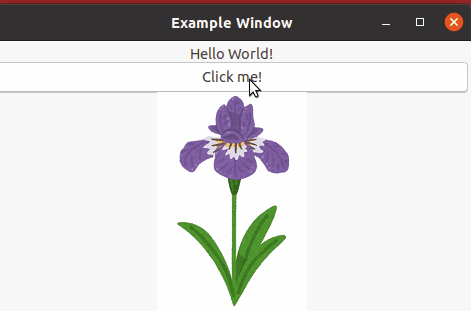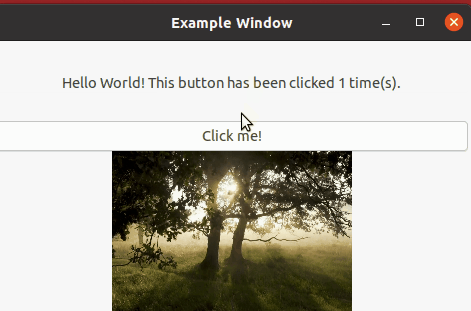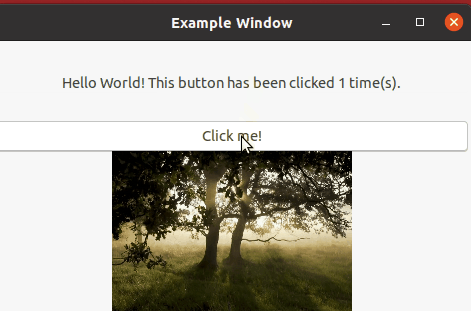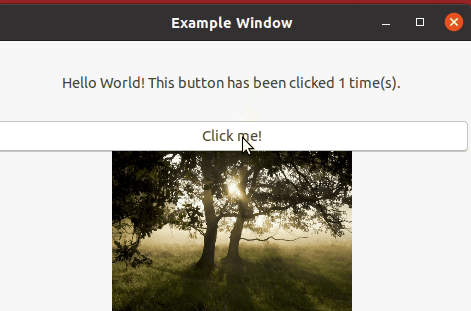
では画像を表示させてみます。
まずWIndowアプリ上への画像表示用のImage Widgetを定義していきます。
MainWindow.gladeにGtkImage Widgetを追加します。
追加にはGladeというアプリを用いると簡単に行えます。
Gladeを用いてGtkImageを追加した結果はこちらのようになります。

今回GtkImage WidgetのIDをtestImgとしました。
命名センスがないことはご了承ください。。。
次にMainWindow.csを変更し表示する画像を定義していきます。
全体のコードはこちらになります。
private MainWindow(Builder builder) : base(builder.GetRawOwnedObject("MainWindow"))
{
builder.Autoconnect(this);
Mat mat = new Mat("画像ファイルパス");
MemoryStream ms = new MemoryStream ();
var bmp = BitmapConverter.ToBitmap(mat);
bmp.Save(ms, ImageFormat.Png);
ms.Position = 0;
testImg.Pixbuf = new Gdk.Pixbuf(ms);
DeleteEvent += Window_DeleteEvent;
_button1.Clicked += Button1_Clicked;
}今回OpenCVSharpで画像を表示するために追加したコードはこちら。
Mat mat = new Mat("画像ファイルパス");
MemoryStream ms = new MemoryStream();
var bmp = BitmapConverter.ToBitmap(mat);
bmp.Save(ms, ImageFormat.Png);
ms.Position = 0;
testImg.Pixbuf = new Gdk.Pixbuf(ms);実際していることは、
Matデータをビットマップデータに変換し、ビットマップデータをメモリに書き込んでからImage Widgetに挿入・表示
です。
これだけ聞くとWindows FormやWPFとOpenCVSharpを組み合わせた画像表示と同じようにできそうですが、、、
こちらのコードの通り、ビットマップデータに変換後Image Widgetに挿入・表示するまでの処理に工夫が必要で簡単にはいかなかったです。
ビットマップデータをImage Widgetに挿入するだけであれば、
Mat mat = new Mat("画像ファイルパス");
var bmp = BitmapConverter.ToBitmap(mat);
testImg.Pixbuf = new Gdk.Pixbuf(bmp );で問題ないように思えます。
しかしこちらのように直接挿入してしまうと
引数 1: は 'System.Drawing.Bitmap' から 'System.IntPtr' へ変換することはできません
といったエラーになってしまいうまく表示できません。
このためあえて、
MemoryStream ms = new MemoryStream(); var bmp = BitmapConverter.ToBitmap(mat); bmp.Save(ms, ImageFormat.Png);
メモリを使用するためのストリームを定義(MemoryStream )し、
こちらにビットマップデータをフォーマットを指定して書き込む。
そして、メモリ上のデータをImage Widgetに挿入することで解決させることが出来ます。
ですが、、、
これだけでは不十分でした。。。
メモリ上にビットマップデータを保存したことにより、MemoryStreamで定義したメモリのアドレスがビットマップデータ分移動してしまうようです。
そこで、メモリ上のデータを挿入する前にMemoryStreamのアドレスを初期化する必要があり、
ms.Position = 0;
を追加。
細かいところが面倒。。。
■実際に動かしてみる
画像が表示されるだけではちょっと悲しいのでボタン押下すると画像が切り替わるコードにして動作させてみたいと思います!!
先ほどのコードからさらに、
private void Button1_Clicked(object sender, EventArgs a)
{
Mat mat = new Mat("画像ファイルパス");
MemoryStream ms = new MemoryStream ();
var bmp = BitmapConverter.ToBitmap(mat);
bmp.Save(ms, ImageFormat.Png);
ms.Position = 0;
testImg.Pixbuf = new Gdk.Pixbuf(ms);
_counter++;
_label1.Text = "Hello World! This button has been clicked " + _counter + " time(s).";
}を追加します。
こちらのコードを追加することにより、最初に表示していた画像からボタン押下時に指定した画像に切り替わる制御になります。
では実行!!
結果はこちらのようになります。
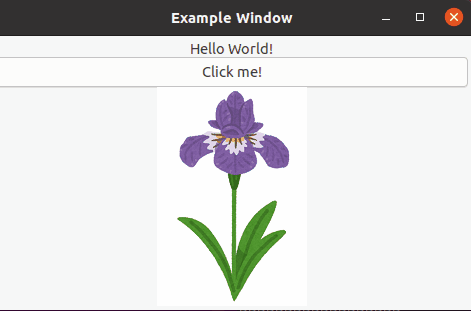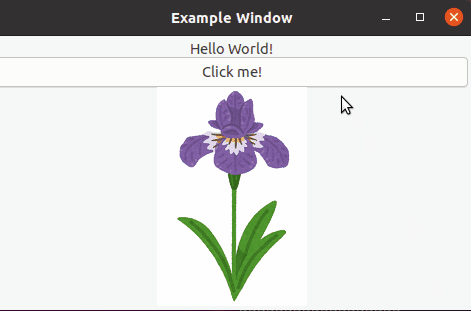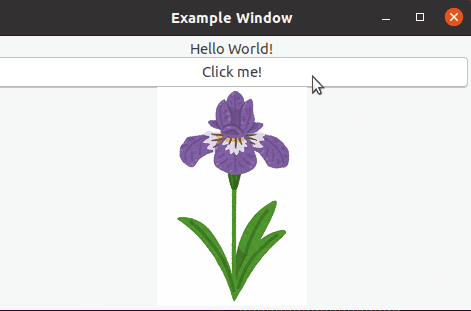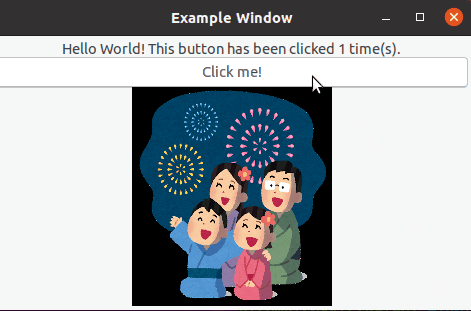
画像が表示された状態でClick meを押下すると画像が切り替わったことがみて分かるかと思います。
■最後に
GtkSharpでOpenCVSharpを動かそうなんて人がほとんどいないためか、情報がほとんどなくとても苦労しました。
ですが、苦労した分出来た時はとてもうれしかったです!!
以前挫折したことが出来るようになってきたということは成長したということ??
今回は画像のみでしたが、動画表示もできたのでこちらも折を見てブログに載せておきたいと思います!!
ちょっとハマりポイントがありましたので忘れないうちにまとめておきます。
dotnetでOpenCvSharpを導入してみる
半年ぐらい前、dotnetでGtk#にてGUIの作成を行う記事を公開しました。
elsammit-beginnerblg.hatenablog.com
そこで下記のようなコメントを残していたのですが、、、
やれておりませんでした。。。
ここまでは出来たのですが、OpenCVとの連携が出来ていないです泣
どうやるのかな??
最終的にはOpenCVと連携したいので、もう少し調べてみます。
また分かったらブログにて備忘録残しておこうと思います!!
今回、dotnetでOpenCvSharpをインストールする方法とGtk#との連携方法をまとめたいと思います。
■dotnetでGtk#を用意
OpenCvSharpをダウンロードする前にdotnetでGtk#を用意するまでをまとめておこうと思います。
まずはGtk#を用意するためのディレクトリを作成し、
さらに作成したディレクトリに移動します。
mkdir gtkApp cd gtkApp
次にこちらのコマンドでGtk#を作成します。
dotnet new gtkapp
コマンド実行が成功していれば、
MainWindow.cs MainWindow.glade Program.cs
といったファイルが生成されているかと思います。
念のため試しに動かしてみます。
こちらのコマンドで実行可能です。
dotnet run
上手く動作すればこちらのような画面が表示されるかと思います。
■dotnetでOpenCvSharpインストール
ではOpenCvSharpをインストールしていきます。
先ほど作成したgtkappディレクトリ配下にてこちらのコマンドを実行します。
dotnet add package OpenCvSharp4 dotnet add package OpenCvSharp4.runtime.ubuntu.18.04-x64
これでOpenCvSharpをdotnetでインストールさせることができます。
すでに環境一式が用意されていたので簡単にインストール出来て便利!!
こちらのOpenCvSharpのインストールですが、
dotnetで新規(GUI)アプリをnewした後に毎度packageをaddする必要があるので注意。
■OpenCvShrpを使ってみる
では実際にOpenCvSharpを組み入れて動かしてみたいと思います。
今回は簡単のために読み出した画像を別画像として保存させてみます。
MainWindow.csのコードはこちらになっているかと思います。
using System;
using Gtk;
using UI = Gtk.Builder.ObjectAttribute;
namespace GtkApp
{
class MainWindow : Window
{
[UI] private Label _label1 = null;
[UI] private Button _button1 = null;
private int _counter;
public MainWindow() : this(new Builder("MainWindow.glade")) { }
private MainWindow(Builder builder) : base(builder.GetRawOwnedObject("MainWindow"))
{
builder.Autoconnect(this);
DeleteEvent += Window_DeleteEvent;
_button1.Clicked += Button1_Clicked;
}
private void Window_DeleteEvent(object sender, DeleteEventArgs a)
{
Application.Quit();
}
private void Button1_Clicked(object sender, EventArgs a)
{
_counter++;
_label1.Text = "Hello World! This button has been clicked " + _counter + " time(s).";
}
}
}こちらのコードに対してまずOpenCvSharpを定義します。
using OpenCvSharp;
次にMainWindowコンストラクタ内にこちらのコードを入力します。
Mat mat = new Mat("画像パス");
Cv2.ImWrite("作成画像ファイル名",mat);最後にクラス名をこちらのように置き換え。
class MainWindow : Gtk.Window
どうやらWindowだけだと、
Gtk.Windowなのか、OpenCvSharp.Windowなのか区別が出来ずエラーになってしまうようです。
先ほどの変更内容を追記したコードがこちら。
using System;
using Gtk;
using OpenCvSharp;
using UI = Gtk.Builder.ObjectAttribute;
namespace GtkApp
{
class MainWindow : Window
{
[UI] private Label _label1 = null;
[UI] private Button _button1 = null;
private int _counter;
public MainWindow() : this(new Builder("MainWindow.glade")) { }
private MainWindow(Builder builder) : base(builder.GetRawOwnedObject("MainWindow"))
{
Mat mat = new Mat("画像パス");
Cv2.ImWrite("作成画像ファイル名",mat);
builder.Autoconnect(this);
DeleteEvent += Window_DeleteEvent;
_button1.Clicked += Button1_Clicked;
}
private void Window_DeleteEvent(object sender, DeleteEventArgs a)
{
Application.Quit();
}
private void Button1_Clicked(object sender, EventArgs a)
{
_counter++;
_label1.Text = "Hello World! This button has been clicked " + _counter + " time(s).";
}
}
}こちらを実行してみます。
dotnet run
ディレクトリ内にCv2.ImWriteで指定したファイルが生成されていればOKです。
■(補足)OpenCvSharpビルド手順
補足としてOpenCvSharpビルド手順をまとめておきます。
まずはGitHubより環境一式をダウンロードします。
git clone https://github.com/GtkSharp/GtkSharp.git
次に
cd opencvsharp/src
でsrc配下に移動し、
mkdir build
でビルドディレクトリを作成。
そして、
cmake .. make sudo make install sudo ldconfig
でビルド+インストールを実施し、最後にパスを通しておきます。
成功すれば、OpenCvSharpExternディレクトリが生成され、
配下にlibOpenCvSharpExtern.soファイルが生成されているかと思います。
こちらがLinuxでOpenCvSharpを用いる際の.soファイルになります。
■最後に
今回はdotnetでOpenCvSharp導入手順についてまとめてみました。
次回はGtk#とOpenCvSharpをてGUI画面上に動画や画像の表示をさせてみたいな。と思っております。
別途monodevelopでもOpenCvSharpを導入しようとしているのだけれどこちらはうまく行かず。。。
monodevelopだとNugetも関わってくるからよく分からなくなってくる。
一応自分でビルドした環境を所定の位置に入れてパス通してみたけど動かず。。。困った。
pandasで2次元配列データを加工する
Kaggleを行う上で用意されているデータの加工は重要なファクターになります。
ですが、Kaggleで用意されているデータは穴が抜けていたり、文字列データであったりと扱いにくい場合が多々あります。
今回はこのような扱いにくいデータを加工する手段についてまとめておこうと思います。
■条件
今回はすでに応募が終了している、
bnp-paribas-cardif-claims-management
コンテストで展開されているデータを利用していきます。
■穴抜けデータの存在確認
まず2次元データに対して穴抜けデータが格納されていないか確認していきます。
コードはこちら。
def kesson_table(df): null_val = df.isnull().sum() percent = 100 * df.isnull().sum()/len(df) cnt = [] val = [] pst = [] for count in range(df.shape[1]): if null_val[count] != 0: cnt.append(count) val.append(null_val[count]) pst.append(percent[count]) cnt = pd.DataFrame(cnt) val = pd.DataFrame(val) pst = pd.DataFrame(pst) kesson_table = pd.concat([cnt, val, pst], axis=1) kesson_table_ren_columns = kesson_table.rename( columns = {0 : 'Number', 1 : '欠損数', 2 : '%'}) return kesson_table_ren_columns kesson_table(train)
kesson_tableが穴抜けデータが存在しないか確認する処理になります。
null_val = df.isnull().sum()
にて各行に対して穴抜けのデータ数をカウントしています。
もし1つでも穴抜けのデータが存在する場合、null_val には0以上の値が格納されます。
このため、
for count in range(df.shape[1]): if null_val[count] != 0: cnt.append(count) val.append(null_val[count]) pst.append(percent[count])
にてnull_valが0ではない。すなわち穴あきデータが存在した場合には確認用の配列に格納していきます。
そして最後に2次元配列でデータを格納し、
値を返します。
cnt = pd.DataFrame(cnt)
val = pd.DataFrame(val)
pst = pd.DataFrame(pst)
kesson_table = pd.concat([cnt, val, pst], axis=1)
kesson_table_ren_columns = kesson_table.rename(
columns = {0 : 'Number', 1 : '欠損数', 2 : '%'})
return kesson_table_ren_columns
■穴抜けデータの保管
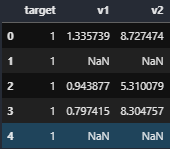
まずはこちらのように、ある数値で埋められた列に対して一部セルが空欄であった場合です。
今回はデータの中央値を穴抜けの箇所に代入していきます。
コードはこちら。
train["v1"] = train["v1"].fillna(train["v1"].median()) train["v2"] = train["v2"].fillna(train["v2"].median()) kesson_table(train)
fillna()にて穴抜けになっている箇所に対して括弧内の値で補完します。
補完する値は先ほど記載した通り、
train["v1"].median() train["v2"].median()
により中央値で補完します。
最後に、
kesson_table(train)
にて補完が完了していることを確認します。
次に文字列データについてです。
こちらのように文字列が格納された列に対して穴あきのケースです。

こちらはデータが少なかったり、大多数が同一のデータであれば補完も同じデータにすればよいのですが、
大抵は、
・データ量が多い
・データ種類複数で大多数のデータが見当たらない
ケースがほとんどです。
そこでまずは各要素とその要素ごとをカウントするところから必要になります。
データ種類とカウント数を算出するコードはこちらになります。
import collections c = collections.Counter(train["v56"]) print(c)
v56が列番号にあたります。
今回は2次元配列を用いているため特定の列に対する1次元配列にしてチェックを行っております。
ここで、要素の抽出と要素毎のカウントを行うにあたり、
collections.Counter
を用いています。
collections.Counterですが、例えばこちらのような配列に対して実行をすると、
list = ['a', 'a', 'a', 'b', 'b', 'c'] c = collections.Counter(list) print(c)
こちらのように各要素数に対するカウント数が算出できます。
# Counter({'a': 4, 'c': 2, 'b': 1})
こちらにより再頻出の文字列が抽出できるため、その文字列で穴あきの部分を補完していきます。
例えばv56列で再頻出な文字列が"BW"であった場合、こちらのようなコードで補完が行えます。
train["v56"] = train["v56"].fillna("BW")
こちらは先ほどの数値補完と同じですね。
■文字列の要素を数値に置き換える。
では次に文字列を数値に置き換えてみます。
先ほどのv56列に対して実施してみます。
コードはこちら。
c = collections.Counter(train["v56"]) count = 0 for k in c: train.loc[train["v56"] == k, "v56"] = count count+=1
先ほどのcollections.Counterで各要素をリスト化させることが出来ます。
このリスト化したデータをfor文により一要素毎に数値に置き換えています。
置き換えにあたり、.locを用いています。
.locですが、
DataFrame型変数.loc['行ラベル名', '列ラベル名']
というように指定することで、指定した行、列についての要素が返ってきます。
今回はこの.locにより行列を指定してその要素に対して数値置き換えを行っています。
ポケモンステータスからタイプを識別してみる Keras編
先日までkerasで2値や多値分類を行ってきました。
elsammit-beginnerblg.hatenablog.com
elsammit-beginnerblg.hatenablog.com
今回はkerasでポケモンのステータスからタイプを分類してみたいと思います。
このタイプ分類ですが、すでにロジスティック回帰などで実施していますが、
kerasだとどれだけ性能が上がるのか確認したく実施してみました!!
elsammit-beginnerblg.hatenablog.com
■利用データ
利用したポケモンのデータですが、こちらに格納されたデータを用いております。
https://drive.google.com/file/d/0Bx6uOB0FHuuSMXdOclZXTHhhSUE/view
■分類内容
今回は、
・ノーマルタイプ
・はがねタイプ
のどちらのタイプなのか分類してみたいと思います。
■データ加工
すでに前回のブログでまとめておりましたが、念のためこちらで再度まとめておきたいと思います。
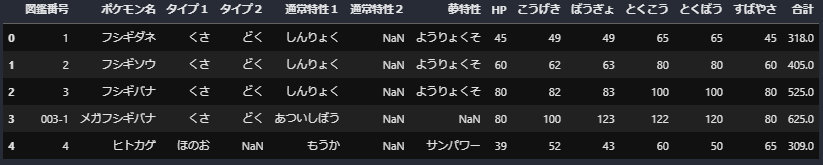
先ほどのデータはこちらのようにステータスと名前が列として用意されておりました。
こちらのリストからノーマルタイプとはがねタイプを抽出。
poketype2 = "ノーマル" poketype3 = "はがね" with codecs.open("/kaggle/input/pokemon-status/pokemon_status.csv", "r", "utf-8", "ignore") as file: df = pd.read_table(file, delimiter=",") nomal1 = df[df['タイプ1'] == poketype2] nomal2 = df[df['タイプ2'] == poketype2] normal = pd.concat([normal1,normal2]) aian1 = df[df['タイプ1'] == poketype3] aian2 = df[df['タイプ2'] == poketype3] aian = pd.concat([aian1,aian2])
次にノーマルタイプかはがねタイプかの判定を行うためのフラグをデータの末尾に追加します。
def type_to_num(p_type,typ):
if p_type == typ:
return 0
else:
return 1
pokemon_m_n = pd.concat([normal, aian], ignore_index=True)
type1 = pokemon_m_n["タイプ1"].apply(type_to_num, typ=poketype3)
type2 = pokemon_m_n["タイプ2"].apply(type_to_num, typ=poketype3)
pokemon_m_n["type_num"] = type1*type2
pokemon_m_n.head()上記コードを組み合わせて実行してみるとこちらのように選択したいタイプが抽出できかつ末尾に判定用のフラグがセットされております。

最後にテストデータとトレーニングデータに分類すればデータ加工・準備は完了です。
全体のコードはこちらになります。
import pandas as pd from pandas import plotting import codecs import numpy as np def type_to_num(p_type,typ): if p_type == typ: return 0 else: return 1 poketype2 = "ノーマル" poketype3 = "はがね" df = pd.read_csv("pokemon_status.csv") nomal1 = df[df['タイプ1'] == poketype2] nomal2 = df[df['タイプ2'] == poketype2] normal = pd.concat([normal1,normal2]) aian1 = df[df['タイプ1'] == poketype3] aian2 = df[df['タイプ2'] == poketype3] aian = pd.concat([aian1,aian2]) pokemon_m_n = pd.concat([normal, aian], ignore_index=True) type1 = pokemon_m_n["タイプ1"].apply(type_to_num, typ=poketype3) type2 = pokemon_m_n["タイプ2"].apply(type_to_num, typ=poketype3) pokemon_m_n["type_num"] = type1*type2 X = pokemon_m_n.iloc[:, 7:13].values y = pokemon_m_n["type_num"].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0) pokemon_m_n.head()
■kerasによるポケモンタイプ分類
ではkerasで分類してみます。
今回はノーマルタイプとはがねタイプを分類してみるため、2値分類になります。
そこで、kerasのモデルをこちらのように作成。
#モデルの定義 model = models.Sequential() model.add(layers.Dense(64, activation="relu", input_shape=(6, ))) model.add(layers.Dropout(0.2)) model.add(layers.Dense(64, activation="relu")) model.add(layers.Dropout(0.2)) model.add(layers.Dense(1, activation="sigmoid")) #モデルの構築 model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
モデルですが、
説明変数は6項目ありますので入力層への入力を6次元に設定。
さらに中間層(隠れ層)を64層用意し、
最後にシグモイド関数により2値分類する
といった構成にしました。
さらにモデルを構築するにあたり、
最適化関数としてrmspropを利用しました。
ではこちらのモデルを用いてポケモンのタイプ分類してみたいと思います。
全体のコードはこちら。
import tensorflow as tf from sklearn import datasets from keras.models import Sequential from keras.layers import Dense, Activation from matplotlib import pyplot #モデルの定義 model = models.Sequential() model.add(layers.Dense(64, activation="relu", input_shape=(6, ))) model.add(layers.Dropout(0.2)) model.add(layers.Dense(64, activation="relu")) model.add(layers.Dropout(0.2)) model.add(layers.Dense(1, activation="sigmoid")) #モデルの構築 model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy']) #学習の実行 history = model.fit(X_train,y_train,epochs=100) #エポック毎のaccuracy結果グラフ化 pyplot.plot(history.history['accuracy']) pyplot.title('model accuracy') pyplot.ylabel('accuracy') pyplot.xlabel('epoch') pyplot.legend(['train', 'test'], loc='upper left') pyplot.show() #評価の実行 score = model.evaluate(X_test,y_test,batch_size=1) print(score[0]) print(score[1])
エポック数ですが100を設定しました。
トレーニングした結果はこちら。
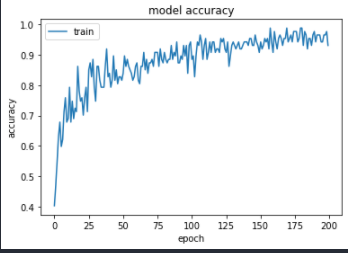
テスト結果ですが、
Loss:0.279 Accuracy:0.908
となりました。
結構高い結果が得られました!!
しかしながら、以前実施したロジスティック回帰の場合には0.943であったので少し悪い結果になってしまいました。。。
■別のタイプで確認してみる
ノーマル、はがねタイプの分類では負けてしまいましたが、、、
ほのお、みずタイプでロジスティック回帰とKerasで比較をおこなってみました。
結果ですが、
【ロジスティック回帰】
testデータに対するscore: 0.738
【Keras】
testデータに対するscore:0.803
といった結果になりタイプによっては性能が高いことが分かりました。
■最後に
タイプによってはKerasの方が性能がよさそうですね。
どんな法則があるのでしょう??
ちょっと後で調べてみたいな!!と思います。