Yoloによる物体検知と動画再生Webアプリを組み合わせてみる
前回、Yoloを用いて画像に対する物体検知を行いました。
elsammit-beginnerblg.hatenablog.com
今回はこちらのYoloによる物体検知と以前作成したWebアプリを組み合わせ、動画再生中に物体検知するWebアプリを作成していきたいと思います。
■条件
すでに動画再生アプリが作成されておりかつ、以前ご紹介したyolov3-tf2がインストール済みであることが条件です。
未実装、未インストールの場合にはこちらをご参考に作成、インストールしてください。
elsammit-beginnerblg.hatenablog.com
elsammit-beginnerblg.hatenablog.com
■環境
・OS:Windows 10
・ディストリビューション:anaconda
■試しにyolov3-tf2で動画再生時の物体検知を行ってみる
まずはyolov3-tf2単体で動画再生を行い、実力を確認してみたいと思います。
今回用いる動画はこちらになります。

yolov3-tf2での動画再生しながら物体検出の方法(コマンド)はこちらになります。
【yolov3】
python detect_video.py --video path_to_file.mp4
【yolov3-tiny】
python detect_video.py --video path_to_file.mp4 --weights ./checkpoints/yolov3-tiny.tf --tiny
ではそれぞれこちらのコマンドを用いて動画再生してみます。
まずはyolov3から試してみます。
【yolov3】

左上に各フレーム毎の処理時間が記載されているのですが、、、
概ね300ms
ちょっと遅いですね。
元の映像と比較してもカクカクです。。。
一方で検出性能は抜群!!ほぼ全ての人に対して検出が行えております。
続いてyolov3-tiny。
【yolov3-tiny】

こちらは打って変わって検出精度はまばらですね。。。
一方で各フレームでの処理時間は60msh程度とかなり処理速度が早いです。
カクカク動くのが嫌だったので、Webアプリにはyolov3-tinyを使用することにしました。
以降はyolov3-tinyを用いた動画再生アプリを作成していきます。
■Webアプリ作成(フォルダ構成)
ではWebアプリ作成に移ります。
まずはフォルダ構成です。
こちらの通りになっております。
赤字が前回と比較して新規追加ファイルになります。
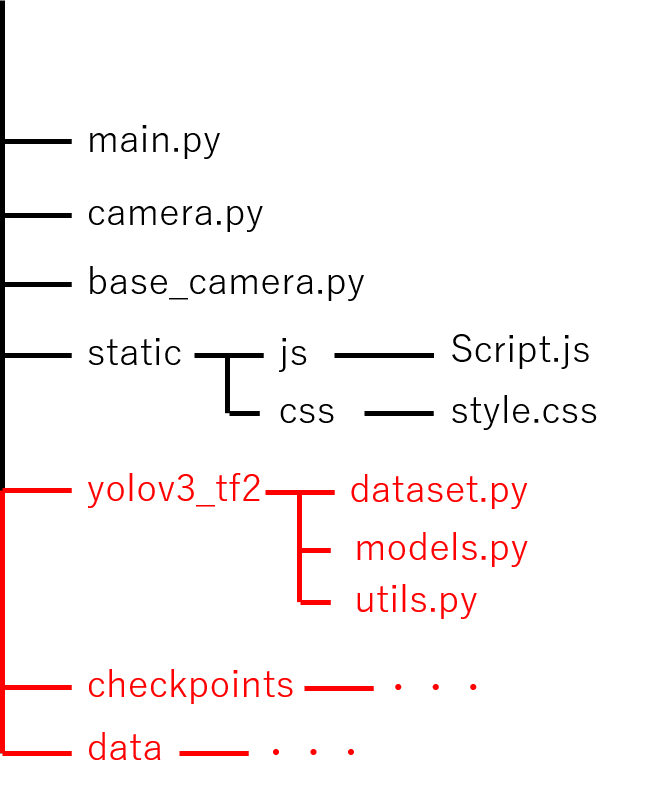
追加しているのはYolov3での学習済みデータになります。
先ほど使用したyolov3-tf2フォルダ内のdata、checkpointsをコピーして持ってきます。
■Webアプリ作成(コード修正)
では実際にコード修正を進めていきます。
前回作成したファイルから修正するファイルはcamera.py、base_camera.pyになります。
まずはcamera.pyから。
コードはこちら。
import time from base_camera import BaseCamera import cv2 import time import cv2 import tensorflow as tf from yolov3_tf2.models import ( YoloV3, YoloV3Tiny ) from yolov3_tf2.dataset import transform_images from yolov3_tf2.utils import draw_outputs class Camera(BaseCamera): counter = 0 speed = 1 stop = True rewindFlg = False progress = 0 MoviePath = '動画ファイルパス' cap = cv2.VideoCapture(MoviePath) if (cap.isOpened()== False): print("File Open Error") frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) @staticmethod def frames(): physical_devices = tf.config.experimental.list_physical_devices('GPU') for physical_device in physical_devices: tf.config.experimental.set_memory_growth(physical_device, True) yolo = YoloV3Tiny(classes=80) yolo.load_weights("./checkpoints/yolov3-tiny.tf") print('weights loaded') class_names = [c.strip() for c in open('./data/coco.names').readlines()] print('classes loaded') times = [] while True: if Camera.stop == True: continue ret, frame2 = Camera.cap.read() if ret == True: Camera.counter = Camera.cap.get(cv2.CAP_PROP_POS_FRAMES) Camera.progress = int(Camera.counter / Camera.frame_count * 100) if Camera.speed != 0: SpdNum = Camera.speed*30 if Camera.rewindFlg==True: Camera.counter-=SpdNum if Camera.counter < 0: Camera.counter = 0 Camera.cap.set(cv2.CAP_PROP_POS_FRAMES, Camera.counter) else: Camera.counter+=SpdNum Camera.cap.set(cv2.CAP_PROP_POS_FRAMES, Camera.counter) else: time.sleep(1/30) img = cv2.resize(frame2,(640,480)) img_in = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_in = tf.expand_dims(img_in, 0) img_in = transform_images(img_in, 416) t1 = time.time() boxes, scores, classes, nums = yolo.predict(img_in) t2 = time.time() times.append(t2-t1) times = times[-20:] img = draw_outputs(img, (boxes, scores, classes, nums), class_names) img = cv2.putText(img, "Time: {:.2f}ms".format(sum(times)/len(times)*1000), (0, 30), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 2) yield cv2.imencode('.png', img)[1].tobytes() else: Camera.counter=0 Camera.cap.set(cv2.CAP_PROP_POS_FRAMES, Camera.counter)
基本的にはyolov3-tf2フォルダ内のdetect_video.pyの処理を流用しています。
下記が物体検出のコードとなります。
img = cv2.resize(frame2,(640,480)) img_in = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_in = tf.expand_dims(img_in, 0) img_in = transform_images(img_in, 416) t1 = time.time() boxes, scores, classes, nums = yolo.predict(img_in) t2 = time.time() times.append(t2-t1) times = times[-20:] img = draw_outputs(img, (boxes, scores, classes, nums), class_names) img = cv2.putText(img, "Time: {:.2f}ms".format(sum(times)/len(times)*1000), (0, 30), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 2)
こちらのyolo.predictを行うために学習済みデータが必要になります。
学習済みデータを読み出すために、
physical_devices = tf.config.experimental.list_physical_devices('GPU')
for physical_device in physical_devices:
tf.config.experimental.set_memory_growth(physical_device, True)
yolo = YoloV3Tiny(classes=80)
yolo.load_weights("./checkpoints/yolov3-tiny.tf")
class_names = [c.strip() for c in open('./data/coco.names').readlines()]を追加いたしました。
次にbase_camera.py。
といってもこちらはタイムアウト処理が入っているのですが、
今回追記した処理の初期設定に時間を要している間にタイムアウトが発生してしまい動かなくなってしまいます。
そこで、タイムアウト処理を伸ばすことにしました。
コードはこちら。
if time.time() - BaseCamera.last_access > 100:
frames_iterator.close()
print('Stopping camera thread due to inactivity.')
breakこれで物体検知付き動画再生アプリができました。
■Webアプリを動作させてみる
では、こちらのアプリを動作させてみたいと思います。
動作させた結果はこちら。

うん!!うまく動画再生Webアプリとして動作させることが出来ました!!
検出時間は大体60msなので、検出速度も上々。
Webアプリとして動かすことが出来て満足。
■最後に
今回は動画再生Webアプリを作成しました。
cv2.VideoCapture(MoviePath)のMoviePathをカメラ番号に置き換えれば、カメラからの映像を通して物体検知が行えます。
良かったら試してみてください。
私も試してみましたが、処理速度は十分で検知精度はそこそこ、といった感じでしたw
一応コードはこちらに格納していますので、よろしかったら覗いてみてください。
https://github.com/Elsammit/Flask-VideoApplication