画像中の画素値調査方法 ヒストグラム作成してみた
今回は画像に対してヒストグラムを作成する方法についてまとめていきたいと思います!!
 | 新品価格 |
今後、画像に対して機械学習を行おうと思った時に画像処理関係の処理は覚えておいて損はないかな?と思い試してみました。
その中でも色情報の抽出はやってみたいな?と思い立ったのでいい内容ないかな?と考えてみたところ、
まずは基本である、画像内の色情報を抽出してみようと思い立ち、実施しました。
■画像でのヒストグラムについて
画像処理でのヒストグラムでは、横軸を諧調値(0~255)、縦軸を各諧調毎の画素数を取ります。
要するに、
「対象とした画像に対して各諧調毎に画素数はいくつか?」
を示します。
、、と言葉だけですとわかりにくいかと思うので、こちらのBlue(0,0,255)画像を用いてヒストグラムを作成いたします。

少し脱線しますが、
こちらのblue画像はnumpyとopencvを用いて、こちらの方法で生成させることができます。
import cv2
import numpy as np
HEIGHT = 256
WIDTH = 320
img_bgr = np.zeros((HEIGHT, WIDTH, 3))
img_bgr += [0,0,255][::-1]
cv2.imwrite('blue.png',img_bgr)このblue画像に対してヒストグラムを作成してみますと、
B成分のみを抽出したヒストグラムは、

B、G成分のみを抽出したヒストグラムは、

となります。
今回の画素数は81920(256×320)になります。
その全てがB成分となるため、255成分が81920になります。
RG成分に対しては諧調なし(0諧調が81920)ですので、ヒストグラム上は諧調が0で81920になります。
■各諧調毎のヒストグラム作成
先ほどお見せしたヒストグラムを作成するためのコードはこちらになります。
※青色画像はすでに用意済みの場合のコードです。
import cv2
import numpy as np
import matplotlib.pyplot as plt
HEIGHT = 256
WIDTH = 320
img_bgr = cv2.imread("blue.png")
img_bgr = cv2.resize(img_bgr,(WIDTH, HEIGHT))
b, g, r = img_bgr[:,:,0], img_bgr[:,:,1], img_bgr[:,:,2]
img_histb, img_bins = np.histogram(np.array(b).flatten(), bins=np.arange(256))
img_histg, img_bins = np.histogram(np.array(g).flatten(), bins=np.arange(256))
img_histr, img_bins = np.histogram(np.array(g).flatten(), bins=np.arange(256))
plt.plot(img_histb, color='#0000FF')
plt.plot(img_histg, color='#FFFF00')
plt.plot(img_histr, color='#FFFF00')
plt.show()まず、こちらにてRGB画像をR成分、G成分、B成分の画像に分割します。
b, g, r = img_bgr[:,:,0], img_bgr[:,:,1], img_bgr[:,:,2]
そして、
np.array(img2次元画像データ).flatten()
により、2次元データ(配列)を1次元データ(配列)に変換し、
numpyのヒストグラムによりヒストグラムを作成します。
img_histb, img_bins = np.histogram(np.array(b).flatten(), bins=np.arange(256)) img_histg, img_bins = np.histogram(np.array(g).flatten(), bins=np.arange(256)) img_histr, img_bins = np.histogram(np.array(g).flatten(), bins=np.arange(256))
ここで、
bins=np.arange(256)
横軸を0~256に明示的に指定することを意味します。
■試しに写真でヒストグラムを作成
青色のみの画像だとちょっと残念なので、こちらの画像でヒストグラムを作成してみます。

結果はこんな感じです。

それぞれ、
赤:R成分
青:B成分
緑:G成分
の諧調情報になります。
海の領域が多いので青の諧調が高い画素が多くありますね!!
別の画像としてこちらでも確認。

ヒストグラムを作成してみると、

という感じになりました!!
全体的に白色だけど暗いから諧調低くてRGBが同じところに重なっているのかしら?
pythonでのスクレイピングによる画像収集方法
前回Kerasを用いた画像識別を行いました。
elsammit-beginnerblg.hatenablog.com
こちらのブログの中では、画像の収集方法については触れませんでした。
今回は自分が用いた画像収集方法である、スクレイピングについてまとめたいと思います!!
スクレイピングはpythonを用います。
 | Pythonスクレイピングの基本と実践 データサイエンティストのためのWebデータ収集術 impress top gearシリーズ 新品価格 |
■スクレイピングとは?
スクレイピングとは、
データを収集した上で加工しやすくすること
です。
似た言葉にクローリングがありますが、
クローリングとは、インターネット上に存在するWebサイト間を行き来し、それらの情報を収集することです。
よく知られた例として、検索エンジンがサイトをインデックスする際にも、クローリングが行われています。
スクレイピングは注意して行わなければなりません。
スクレイピングを行うと、下記に抵触する可能性があります。
著作権法(昭和45年5月6日)と業務妨害罪(刑法第二編第三十五章「信用及び業務に対する罪」(第233条 - 第234条 - 第234条の2))
ただデータをそのまま公開したりせず、自分なりの加工・表現を加えたり、
相手サイトに大幅な負荷をかけない
などの注意が必要になります!!
■スクレイピング前準備
pythonでスクレイピングを行う上でBeautifulSoupを利用します。
BeautifulSoupはこちらでダウンロード・インストールすることができます。
pip install beautifulsoup4
■スクレイピング実行
今回はいらすとや上で画像取集のためのスクレイピングになります。

全体ソースコードはこちらになります。
import time import re import requests from pathlib import Path from bs4 import BeautifulSoup OutPutFolder = Path('test') OutPutFolder.mkdir(exist_ok=True) url = 'スクレイピング対象のURL' LinkList = [] html = requests.get(url).text soup = BeautifulSoup(html,'lxml') List = soup.select('div.boxmeta.clearfix > h2 > a') for a in List: print(a) link_url = a.attrs['href'] LinkList.append(link_url) time.sleep(1.0) for page_url in LinkList: page_html = requests.get(page_url).text page_soup = BeautifulSoup(page_html, "lxml") img_list = page_soup.select('div.entry > div > a > img') for img in img_list: img_url = (img.attrs['src']) filename = re.search(".*\/(.*png|.*jpg)$",img_url) save_path = OutPutFolder.joinpath(filename.group(1)) time.sleep(1.0) try: image = requests.get(img_url) open(save_path, 'wb').write(image.content) print(save_path) time.sleep(1.0) except ValueError: print("ValueError!")
まず、
OutPutFolder = Path('test') OutPutFolder.mkdir(exist_ok=True)
により、ダウンロード先のフォルダが存在しない場合に新規に作成します。
次にこちらにより、url上のhtml形式の文字列を収集いたします。
そして、その中で特定のタグ収集を行います。
今回は、
div.boxmeta.clearfix > h2 > a
になります。
html = requests.get(url).text soup = BeautifulSoup(html,'lxml') List = soup.select('div.boxmeta.clearfix > h2 > a')
こちらのタグですが、ホームページ上で右クリック⇒検証を押下すればhtmlが表示されるので、
こちらから必要なタグやstyleを選択すればOKです。
そしてそして!!
for a in List: print(a) link_url = a.attrs['href'] LinkList.append(link_url) time.sleep(1.0)
こちらでリンク先URLの一覧を取得します。
※リンクから収集するのでなければ、こちらの処理は不要になります。
最後に、リンク先ホームページ上から、
imgタグを収集し、画像をダウンロードしていきます。
for page_url in LinkList: page_html = requests.get(page_url).text page_soup = BeautifulSoup(page_html, "lxml") img_list = page_soup.select('div.entry > div > a > img') for img in img_list: img_url = (img.attrs['src']) filename = re.search(".*\/(.*png|.*jpg)$",img_url) save_path = OutPutFolder.joinpath(filename.group(1)) time.sleep(1.0) try: image = requests.get(img_url) open(save_path, 'wb').write(image.content) print(save_path) time.sleep(1.0) except ValueError: print("ValueError!")
以上です!!
今まで作ったアプリを集めたホームページ作成
今まで作成したゲームやアプリを整理したいのと、一覧で紹介したいな、と思い立ち、
紹介ページを作成してみました!!
※今回は技術紹介ではないのです。
作成はReactで行いました!!
作成したホームページはこんな感じ。

ASPではないですし、レイアウトがこだわれていないので別にReactでなくてもよかったなと思いました😅
htmlとcssしか用いていないですしね😅
後、やはりデザインが上手くできないですね。
今回、こちらの本を参考にしてデザイン作ってみたのですが、、、
なんかうまくできないんだよな。。。
本に記載されている、
「2カラムのWebサイトを作成する」
を元に作成してみており、レイアウトはそれなりになっているのでそこは満足なのですが。
細かいデザインをもっとこだわるといいのかな??
 | 1冊ですべて身につくHTML & CSSとWebデザイン入門講座 新品価格 |
もっと動きを出したいのでjavascriptを使っていきたいのと、せっかくReact使っているので、
React使っている利点をもっと出した感じのホームページにしていきたいと思います!!
後でgithub Pageでホームページ公開したいと思います。
※現在、githubにcommit中ですw
まだPC用しか出来ておらず、スマホだと表示が切れてしまいます。
時間がある時にレスポンシブ対応も行っていきたいと思います。
やりたいこと、やらなきゃなことがたくさんありますが、、、
頑張るぞ~~~!!👍
Kerasを用いた画像識別
前回、ポケモンのステータスからポケモンのタイプを判定するソフトを作成しました。
elsammit-beginnerblg.hatenablog.com
elsammit-beginnerblg.hatenablog.com
今回は画像の識別を行いたいと思います。
識別画像ですが、いらすとやの犬と猫を行います。
いらすとやの犬と猫はこんな感じですね。

今回はすでにいらすとやの犬と猫の画像が集まっていること前提で記載させていただきます。
自分は犬、猫ともに60枚程度用意いたしました。
■画像識別モデル
識別モデルですが、下記を参考(ほぼコピー)に作成いたしました。
画像認識で「綾鷹を選ばせる」AIを作る - Qiita
後でモデルについてはまとめて行いたいと思います。
今回利用するモデルはこんな感じと思っていただければ、と思います。
def CNN():
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation="relu"))
model.add(layers.Dense(2,activation="sigmoid"))
model.summary()
return modelこちらのモデルをコンパイルしていきます。
コンパイルコードはこちら。
def Compile():
model = CNN()
model.compile(loss="binary_crossentropy",
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=["acc"])
return model
■学習データ準備
先ほどのモデルに学習させるために、画像データと犬・猫のフラグを関連づけや画像データ整備等を行っていきます。
まずは画像の読み出しと画像に対する犬、猫データを組み合わせてリストを作成していきます。
ソースはこんな感じです。
allFiles = []
def zyunbi():
for imgpath in nekofiles:
imgpath = "./neko/" + imgpath
allFiles.append((0,imgpath))
for imgpath in inufiles:
imgpath = "./inu/" + imgpath
allFiles.append((1,imgpath))
random.shuffle(allFiles)
th = math.floor(len(allFiles) * 0.8)
train = allFiles[0:th]
test = allFiles[th:]
X_train, y_train = make_sample(train)
X_test, y_test = make_sample(test)
xy = (X_train, X_test, y_train, y_test)
np.save("irasuto_data.npy", xy)今回、猫:0、犬:1として[画像,識別データ]でallFilesにリスト追加しております。
作成したリストに対してランダムに並び変えた後、テストデータと訓練用データに分けます。
このmake_sampleにて訓練データやテストデータに対して、
説明変数X:画像、目的変数Y:識別データ(犬 or 猫)
の登録を行います。
ソースはこんな感じ。
def make_sample(files):
global X, Y
X = []
Y = []
for cat, fname in files:
add_sample(cat, fname)
add_rotate_sample(cat, fname, 45)
add_rotate_sample(cat, fname, 90)
add_rotate_sample(cat, fname, 135)
add_rotate_sample(cat, fname, 180)
add_rotate_sample(cat, fname, 270)
return np.array(X), np.array(Y)
def add_sample(cat, fname):
img = Image.open(fname)
img = img.convert("RGB")
img = img.resize((150, 150))
data = np.asarray(img)
X.append(data)
Y.append(cat)
def add_rotate_sample(cat, fname, rotates):
img = Image.open(fname)
img = img.convert("RGB")
img = img.resize((150, 150))
img = img.rotate(rotates)
data = np.asarray(img)
X.append(data)
Y.append(cat) ここで、60枚程度では流石に足りなかったので、もともと保存していた画像を45°~270°に回転させて、データを増やしました。
5パターン追加したため、360枚のデータが登録できました。
最後に、
np.save("irasuto_data.npy", xy)で分類したデータ群を保存します。
※保存しておくと、あとで使いまわすことができるため便利。
■モデル学習
先ほどコンパイルしたモデルに対して、事前準備したデータで学習していきます。
学習する場合にはこちらの通り、model.fitにより行えます。
model = model.fit(X_train,
Y_train,
epochs=10,
batch_size=6,
validation_data=(X_test,Y_test))モデル学習全体のコードはこちら。
# テストデータ、訓練データ用意
X_train, X_test, Y_train, Y_test = MakeTrainData()
#モデル準備
model = Compile()
model = model.fit(X_train,
Y_train,
epochs=10,
batch_size=6,
validation_data=(X_test,Y_test))
■モデル学習結果
学習結果はこんな感じになりました。


エポックが9以降でaccuracyが減少し、lossが増加傾向にあるため、過学習起こしているようです。
もう少しデータ増やした方がいいかな??
もしくはエポックを減らすか。
どちらにせよ何か手を打たなければならないかな😅
結果格納のために使用したコードはこちらです。
def ShowGraph(model):
acc = model.history['acc']
val_acc = model.history['val_acc']
loss = model.history['loss']
val_loss = model.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.savefig('accuracy.jpg')
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.savefig('loss.jpg')
■実際に犬・猫判定してみた
ちょっと学習が不十分ですが、、、
せっかくなので、犬・猫判定してみました!!
とその前に!!
学習させたモデルを保存しておき、使いたい時に使えるようにしたいと思います。
保存のためのコードはこちらになります。
json_string = model.model.to_json()
open('irasutoya_predict.json', 'w').write(json_string)
hdf5_file = "irasutoya_predict.hdf5"
model.model.save_weights(hdf5_file)どうやらモデルと重み付けは別ファイルで保存する必要があるようです。
判定用のコードはこんな感じ。
model = model_from_json(open('irasutoya_predict.json').read())
model.load_weights('irasutoya_predict.hdf5')
img_path = str("test/pet_ha_clean_neko.png")
img = image.load_img(img_path,target_size=(150, 150, 3))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
features = model.predict(x)
if features[0,0] == 1:
print("猫です")
else:
print("犬です")先ほど保存した学習済みモデルを読み出し、
予測したい画像を読み出し、
評価して、結果を確認する。
以上です!!
実際にはこんな感じで判定できました。
「猫」と判定しOK。

「犬」と判定しOK。

「猫」と判定しNG。

やはり、ちょっと安定してない気がしますね😅
■最後に
画像に対しても識別する方法を学ぶことができました!!
ただ、モデルの部分は他の人のを完全流用。。。
機械学習にとって一番重要な部分を他力本願にしてしまったので、これからモデルの作り方についても学んでいきたいと思います!!
以前から欲しいと思っていたこちらの本が届きましたので、読んで勉強しよっと😆
 | ゼロから作るDeep Learning ?Pythonで学ぶディープラーニングの理論と実装 新品価格 |
ARマーカー作成とARでの画像表示
さて、今回はAR技術についてです。
ポケモンGoやドラクエウォークなど、ARを使ってキャラクターを現実世界に表示させるアプリがありますが、
ARってどうやって作ればいいんだろう??🤔と思い、調べてみました。
ARマーカー作成と表示にあたりPythonでOpenCVを用いたいと思います。
Pythonのバージョンは"3.7.4"を用います。
 | 独学プログラマー Python言語の基本から仕事のやり方まで 新品価格 |
■環境構築
OpenCVにてARマーカーの作成や読み込みを行うにあたり、
"aruco"ライブラリが用意されているとのこと!!
早速、
import cv2 aruco = cv2.aruco ~~~
を実行してみたところ、
AttributeError: module 'cv2.cv2' has no attribute 'aruco'
といったエラーが発生!!
どうやら、opencv-pythonと"opencv-contrib-python"が必要なようです!!
opencv-contrib-python入れてないや😅
ということで、
pip install opencv-contrib-python
を実行!!
インストール成功!!👍
こちらを実現したところ問題なく通った!!
import cv2 aruco = cv2.aruco ~~~
■ARマーカー作成
マーカー作成のソースコードはこちら。
ちょっと欲張って10枚のマーカー作成させ、
それらを5×5に配置して1枚の画像として出力させてみました。
※もちろんそれぞれ単体のマーカー生成も行っております。
import cv2.aruco
import numpy as np
aruco = cv2.aruco
dictionary = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
SIZE = 150
ImgList1 = []
ImgList2 = []
WiteList = []
def arGenerator():
img_white = np.ones((SIZE,SIZE, 3),np.uint8)*255
for i in range(1,6):
fileName = "ar_" + str(i) + ".png"
generator = aruco.drawMarker(dictionary, i, SIZE)
cv2.imwrite(fileName, generator)
ImgList1.append(cv2.imread(fileName))
ImgList1.append(img_white)
WiteList.append(img_white)
WiteList.append(img_white)
convImg1 = cv2.hconcat(ImgList1)
convWhite = cv2.hconcat(WiteList)
for i in range(6,11):
fileName = "ar_" + str(i) + ".png"
generator = aruco.drawMarker(dictionary, i, SIZE)
cv2.imwrite(fileName, generator)
ImgList2.append(cv2.imread(fileName))
ImgList2.append(img_white)
convImg2 = cv2.hconcat(ImgList2)
TestList = [convImg1, convWhite, convImg2]
convImg3 = cv2.vconcat(TestList)
cv2.imshow('ArMarker1',convImg3)
cv2.imwrite("Result.jpg", convImg3)
cv2.waitKey(0)
arGenerator()こちらでARマーカーの形状や形式??を定義。
dictionary = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
そして、実際にARマーカーを生成している箇所はこちら。
generator = aruco.drawMarker(dictionary, i, SIZE)
後はimwriteでpng画像にした後にそれらの情報をリスト化して5×5に置き換えているのみなので割愛しますが、
cv2.hconcat()
が渡されたリスト情報を元に1枚ずつ横に画像を並べ、
cv2.vconcat()
が縦に画像を並べます。
生成されるARマーカーはこんな感じになります。

■ARマーカー読み取り
ARマーカーを読み取り、ARマーカー上に画像を表示するコードはこちら。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import cv2
aruco = cv2.aruco #arucoライブラリ
dictionary = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
img1 = cv2.imread("makewani.png")
img2 = cv2.imread("hamstar.png")
img3 = cv2.imread("mogura.png")
def ConvImg(corners, i, img, convimg):
x=int(corners[i][0][0][0])
y=int(corners[i][0][0][1])
w=int(corners[i][0][2][0]) - int(corners[i][0][0][0])
h=int(corners[i][0][2][1]) - int(corners[i][0][0][1])
if w > 0 and h > 0:
convimg = cv2.resize(convimg,(w,h))
img[y:y+h,x:x+w] = convimg
return img
def arReader():
cap = cv2.VideoCapture(0) #ビデオキャプチャの開始
while True:
ret, frame = cap.read() #ビデオキャプチャから画像を取得
Height, Width = frame.shape[:2] #sizeを取得
img = cv2.resize(frame,(int(Width),int(Height)))
corners, ids, rejectedImgPoints = aruco.detectMarkers(img, dictionary) #マーカを検出
aruco.drawDetectedMarkers(img, corners, ids, (0,255,0)) #検出したマーカに描画する
try:
if corners != []:
for i in range(len(ids)):
if ids[i] == 10:
img = ConvImg(corners, i, img, img1)
if ids[i] == 5:
img = ConvImg(corners, i, img, img2)
if ids[i] == 3:
img = ConvImg(corners, i, img, img3)
cv2.imshow('drawDetectedMarkers', img) #マーカが描画された画像を表示
cv2.waitKey(1) #キーボード入力の受付
except:
print("error")
cap.release() #ビデオキャプチャのメモリ解放
cv2.destroyAllWindows() #すべてのウィンドウを閉じる
arReader()処理としては大きく分けて、
・ARマーカー読み取り
・読み取ったARマーカー上に画像を表示
の2つです。
まず、ARマーカー読み取り
まずはいつもの。
ret, frame = cap.read() #ビデオキャプチャから画像を取得 Height, Width = frame.shape[:2] #sizeを取得 img = cv2.resize(frame,(int(Width),int(Height)))
カメラからキャプチャ画像を取得。
そして取得したキャプチャ画像に対して、
corners, ids, rejectedImgPoints = aruco.detectMarkers(img, dictionary) #マーカを検出
によりARマーカを読み取り。
返り値ですが、
・corners:マーカーの4角の座標情報
・ids:登録されているid値
となります。
デバッグも兼ねて、
aruco.drawDetectedMarkers(img, corners, ids, (0,255,0)) #検出したマーカに描画する
を入れております。
こちらは、読み取ったARマーカーの領域やid値をキャプチャ画像に重ね合わせる処理を行っております。
次にARマーカー上に画像重ね合わせです。
def ConvImg(corners, i, img, convimg):
x=int(corners[i][0][0][0])
y=int(corners[i][0][0][1])
w=int(corners[i][0][2][0]) - int(corners[i][0][0][0])
h=int(corners[i][0][2][1]) - int(corners[i][0][0][1])
if w > 0 and h > 0:
convimg = cv2.resize(convimg,(w,h))
img[y:y+h,x:x+w] = convimg
return imgにて重ね合わせ処理を実行しております。
cornersですが、4次元配列で情報が保存されております。
1次元目にARマーカーの各角x座標、y座標が格納。
2次元目にARマーカーの各角番号が格納されています。
角番号の割り振りですが、時計回りに0~3で格納されております。
そして、4次元目に読み取ったマーカー番号が格納されています。
と言っても文字だけだとわかりにくいので図で表すとこんな感じです。

この図を例に1番目のマーカーの左上のx座標を取得したい場合には、
X = corners[1][0][0][0]
となります。
右下のy座標の場合には、
Y = corners[1][0][2][1]
ですね。
実際に動かしてみるとこんな感じになりました。

なかなかですね😅
■最後に
ARでの画像表示するだけなら結構簡単に行えるんだな!!と思いました。
だけど、、、
最近のARで表示される画像って3次元なんですね。。。
ARマーカーを読み取った際の向きや角度も検出できるようなので、それを用いて切り替えるのかな?🤔
https://sgrsn1711.hatenablog.com/entry/2018/02/15/224615
3次元画像をどうやって表示させるか?はまだ調べなければ、、
う~~ん。奥が深いです。
HTML & CSSとWebデザインを読んでみました
HTMLとCSSホームページ作ってみたいな!!と思っているのですが、どうもうまく作れなかったので
AmazonでHTMLやCSSの参考書で1位を取っていたこちらを読んでみました!!
 | 1冊ですべて身につくHTML & CSSとWebデザイン入門講座 新品価格 |
■参考書記載内容
大きく、
・HTMLとCSSの基礎
・学んだ基礎を用いてホームページ作成の流れ
の2構成で書かれていました。
HTMLとCSSの基礎ではホームページとは何か?から記載されており、
これからWebページを作成したい初心者プログラマにもとても分かりやすく記載されておりました。
著者はデザイナーのようで、
”どのようなレイアウトにすれば見やすいページを作成できるのか?”が詳しく書かれておりました。
ユーザビリティの高いホームページとはどういうレイアウトか?を目的毎に記載!!
デザイン性が著しく低い私にとって、ありがたかったです!!
ここだけでも買ってよかったと思ったポイントです!!
基礎が終わった後は仮想カフェショップのホームページを作る場合を例に、
・メインページ
・Newsページ
・メニューページ
・Contactページ
をそれぞれどのように作ればよいのか?が詳しく書かれておりました。
最後のContactページでは、googleMapやTwitterなどの外部サイトとどのようなコードを書けば連携できるのか?を分かりやすく・詳しく書かれておりました。
■参考書を読んだ感想
かなり初心者向けだな!!と感じました。
各作業ごとに文章と画像がわかりやすく・見やすく配置されているのがGood👍
初心者でも躓きにくいかな?と呼んでいて感じました!!
少なくとも自分は書いている内容がスッと頭に入ってきました!!
何より個人的にGood Pointはデザインについて詳しく書かれていた点です!!
様々なケースでどのようなレイアウトにすればよいのか?を書かれており、
今からホームページ作るにあたってとても参考になる書籍だな!!と感じました👍
後、各チャプター毎にコラム?的なページがありこちらが豆知識的なことが書かれており、
とても勉強になりました!!
(各色ごとのRGB値とか後で見ながら配色したいと思いました)。
■最後に
読み終わった後、"自分でも作れるかも"と思えるようになる一冊でした!!
とても読みやすいですし、Amazonで1位になる理由もわかるなと感じました!!
今後、機会があったらホームページ作ってみたいな!!と思います😁
C#でのFTP ファイル転送
今回はC#でのFTPファイル転送についてまとめていきたいと思います!!
ちょっと興味があり、以前調べたのですが使うことがなく。。。
忘れない内に備忘録として残しておきたいと思います!!
■FTPとは?
超基礎的ですが、一応。
FTPとは「File Transfer Protocol」の略称であり、ファイルを転送・通信するための規格です。
クライアントとサーバ間で、ファイルのアップロード・ダウンロードを行うときに使われるプロトコルのことです。
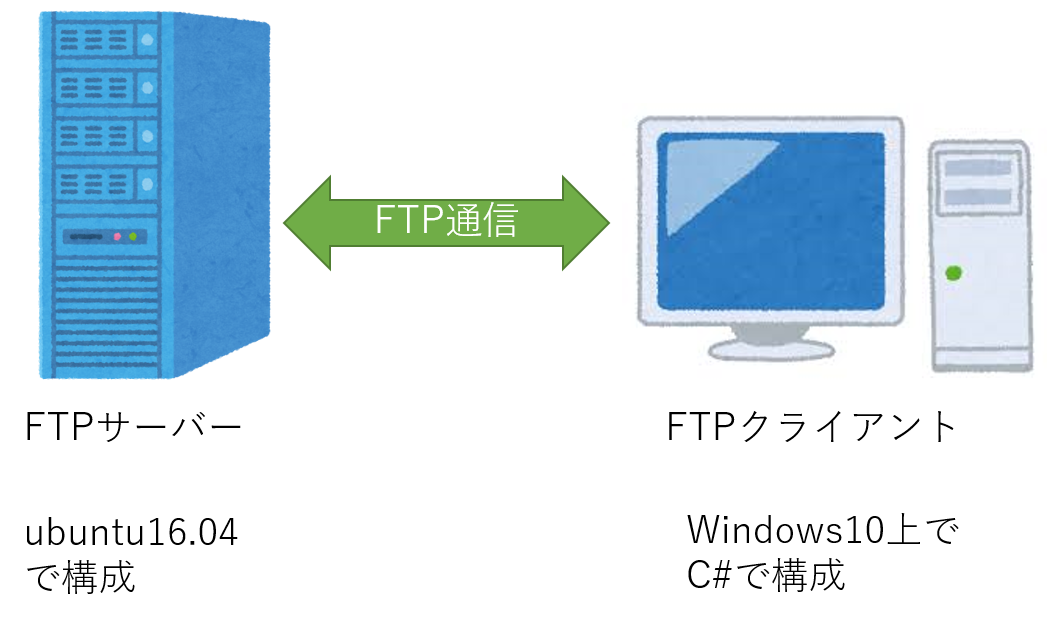
■FTPサーバーへのファイルアップロード
FTPクライアントからのファイルアップロードを行う場合(ファイルダウンロードもですが)、
System.Netを利用するため、前もって、
using System.Net
を定義しておきます。
メインのファイルアップロードですが、コードはこちらになります。
try
{
WebClient wc = new WebClient();
wc.Credentials = new NetworkCredential("ユーザ名", "password");
foreach (string FilePath in FileList)
{
string FileName = System.IO.Path.GetFileName(FilePath); // ファイル名取得.
wc.UploadFile(string.Format("{0}/{1}", FTPpath, FileName), FilePath); // ファイルアップロード.
}
}
catch (Exception e)
{
Ret = -1;
Console.WriteLine(e.ToString());
} WebClient wc = new WebClient();
wc.Credentials = new NetworkCredential("ユーザ名", "password");にてFTPサーバとの接続を実施します。
※ユーザ名、passwordにはFTPサーバ側のユーザ名とパスワードを入力してください。
そして、送信するのはWebClientのUploadFileを用います。
UploadFileの引数は、
UploadFile("送信先パス","送信元ファイルパス")となります。
今回は、string.Formatを用いて、ファイル名とファイルパスを分離して渡しております。
ここで、送信先パスが存在しない場合にはエラーになりますので注意下さい。
FTPサーバー側でフォルダが存在するかをチェックする処理はこちらになります。
アップロード前にパスが存在するか確認するのがよいですね。
WebRequest request = WebRequest.Create(FTPpath);
request.Credentials = new NetworkCredential("ユーザ名", "password");
request.Method = WebRequestMethods.Ftp.ListDirectory; // リクエスト生成(存在するディレクトリチェック)
using (WebResponse res = request.GetResponse()) // ディレクトリ名取得.
{
using (StreamReader sr = new StreamReader(res.GetResponseStream()))
{ Ret = sr.ReadToEnd(); } // ディレクリ名の文字列を生成.
}
wc.Dispose();こちらでFTPpathで指定したファイルパス以降に存在するフォルダリストが取得できます。
request.Method = WebRequestMethods.Ftp.ListDirectory; // リクエスト生成(存在するディレクトリチェック)
■FTPサーバーからのファイルダウンロード
次はサーバーからのファイルダウンロードです。
。。。といってもFTPサーバーへのアップロードとほとんど同じです。
try
{
WebClient wc = new WebClient();
wc.Credentials = new NetworkCredential("ユーザ名", "password");
foreach (string FilePath in FileList)
{
string FileName = System.IO.Path.GetFileName(FilePath); // ファイル名取得.
wc.DownloadFile(string.Format("{0}/{1}", FTPpath, FileName), FilePath); // ファイルダウンロード.
}
wc.Dispose();
}アップロードと異なる点はこちらになります。
wc.DownloadFile(string.Format("{0}/{1}", FTPpath, FileName), FilePath); // ファイルダウンロード.DownloadFileというAPIを用いればFTPからのダウンロードが行えます。
DownloadFileは、
DownloadFile("ダウンロード対象パス", "ダウンロード先パス");となります。
こちらについてもファイルが存在しない場合にはエラーになってしまいます。
ファイルの存在有無は先ほどのWebRequestMethods.Ftp.ListDirectoryで確認することが出来るので、こちらも前もって確認しておくとよいですね。